



How high-quality data and security drive AI/ML success

Artificial Intelligence (AI) and Machine Learning (ML) are reshaping industries, solving complex problems, and delivering business results. Behind every successful AI/ML model lies one factor: high-quality, secure data.
Data is the new fossil fuel. Data powers AI/ML models. Data guides these models to make accurate predictions. Without clean, consistent and well-protected data, these models can fail to deliver reliable results. In this guide, we’ll explore the entire AI/ML data lifecycle—from collection to deployment—and explain how to ensure your data remains both high-quality and secure.
Whether you’re starting an AI project or optimizing an existing one, understanding the role of data is the first step toward success.
Why high-quality and secure data is essential for AI/ML success
AI/ML models are only as good as the data they train on. Think of data as the foundation of a building—if it’s flawed, the entire structure is at risk. Ensuring data quality leads to:
- Accurate Predictions: Clean data minimizes errors in AI/ML models.
- Actionable Insights: Reliable data allows better decision-making.
- Improved Efficiency: Secure data reduces risks like breaches and compliance violations.
At the same time, securing your data is just as critical. Without the right safeguards, sensitive information can be exposed, and trust in your AI/ML solutions will erode.
Challenges in building effective and secure AI/ML models
Lack of clean and consistent data
Imagine trying to train an AI model with incomplete, duplicated, or outdated information. Such issues lead to inaccuracies and biases, making the model unreliable.
Inefficient Data Integration
Organizations often gather data from diverse sources—databases, APIs, IoT devices, and cloud platforms. Integrating these into a unified, accessible system is a major hurdle.
Security Risks
Data breaches, unauthorized access, and mishandling of personally identifiable information (PII) are growing threats. Each week a new major incident is reported. Security lapses can lead to regulatory fines and loss of user trust.
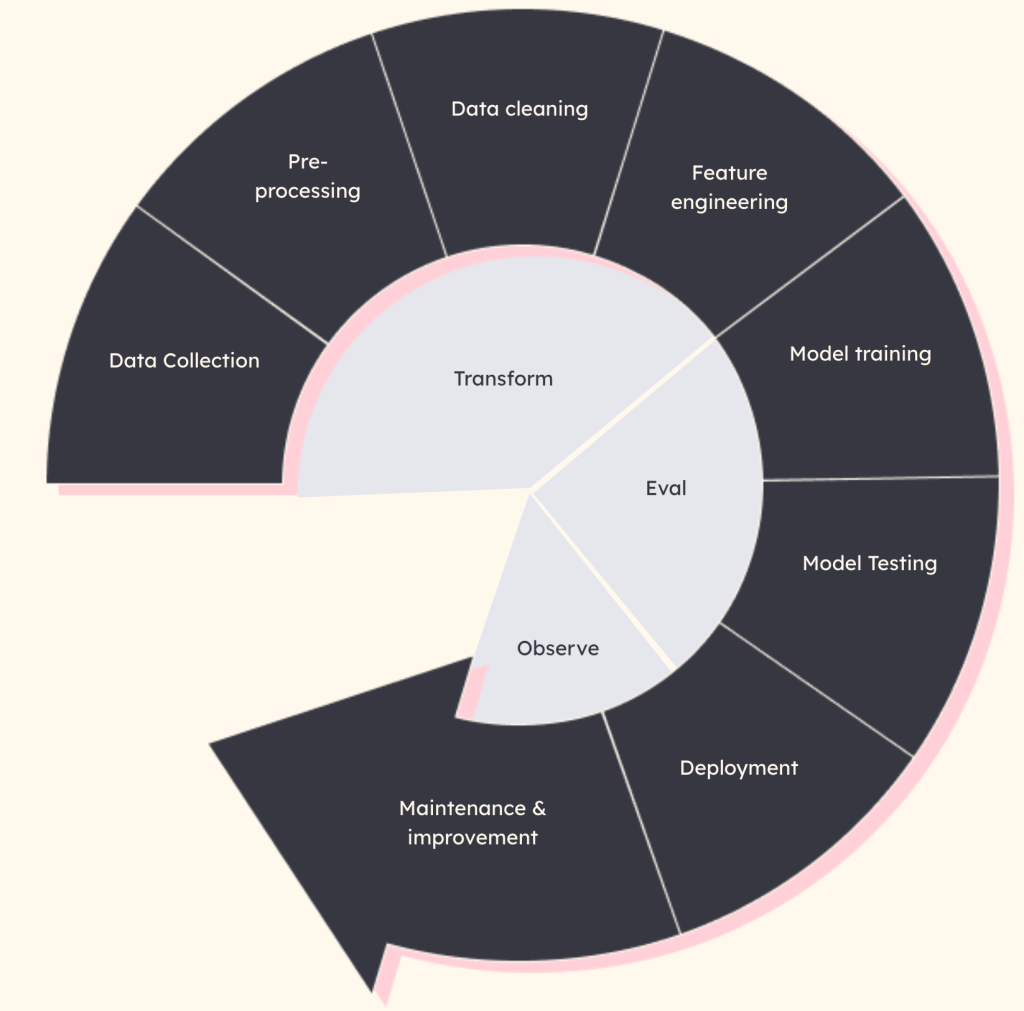
The data lifecycle: from collection to continuous improvement
The journey of AI/ML data follows these key stages:
- Data Collection: Gathering data from multiple sources like sensors, databases, and APIs.
- Pre-Processing: Cleaning and normalizing data for consistency.
- Data Cleaning: Removing errors, duplicates, and inaccuracies.
- Feature Engineering: Extracting the most useful information for training.
- Model Training: Feeding the data into algorithms to develop the AI model.
- Model Testing: Evaluating how well the model performs on unseen data.
- Deployment: Delivering the model into production.
- Monitoring and improvement: Continuously monitoring and improving its performance.
Data strategy and management
Design-Led AI Process
A design-led approach ensures that AI solutions align with business goals. It focuses on three core actions:
- Transform: Adapting data to meet the needs of AI/ML models.
- Eval: Experimenting and tracking how data and models behave in real-world conditions.
- Observe: Continuously improving processes based on performance metrics.
End-to-end security measures
To safeguard sensitive information, follow these steps:
- Zero-Trust Architecture: Implement a security model that assumes no actor, inside or outside the network, is inherently trustworthy. Authenticate, authorize, and encrypt every interaction.
- Data Encryption: Encrypt data both in transit and at rest to prevent misuse.
- Security-Focused Testing: Use automated dataset experiments with tools like LangSmith to test and validate AI responses for accuracy, safety, and security. Integrate human-in-the-loop reviews to verify edge cases and prevent unintended behavior before deploying to production.
- Proactive Monitoring: Set up continuous monitoring tools to track system activity, detect anomalies (e.g., unusual API usage, potential injection attacks), and trigger alerts for action.
Data Ingestion and Integration
Seamless Data Ingestion
Data ingestion involves collecting and importing data from various sources. For AI/ML projects, it’s crucial to ensure the process is both comprehensive and efficient.
Some popular tools for data ingestion include:
- Apache Kafka: Ideal for real-time data streaming.
- AWS Kinesis: Supports large-scale streaming data pipelines.
- Google Pub/Sub: Excellent for real-time messaging.
Effective Integration
After collecting data, the next challenge is integrating it into a unified system. This ensures downstream processes like model training can access data seamlessly.
Building Scalable Data Pipelines
Why Scalability Matters
As your data grows, your pipelines must handle increased volumes without compromising speed or accuracy. Scalable pipelines also maintain data integrity, ensuring consistency across all stages.
Tools for Automation
- Apache Spark: Processes big data quickly and efficiently.
- Databricks: Combines collaboration and scalability for pipeline development.
- Custom Scripts: Tailored ETL (extract, transform, load) scripts using Python or Scala.
Optimizing Storage
Choose between:
- Data Lakes: Ideal for storing unstructured or raw data.
- Data Warehouses: Suited for structured data used in analytics and reporting.
Data Cleaning and Transformation
Common Challenges
Issues like missing values, outliers, or inconsistencies can distort AI/ML models. Cleaning ensures the data is reliable and usable.
Advanced Transformations
- Aggregations: Summarizing data for analysis.
- Enrichments: Adding context to datasets.
- Joins: Combining multiple datasets into one.
Tools
Platforms like Apache Spark and Databricks simplify the cleaning and transformation process.
Feature Engineering for Better Model Accuracy
The Role of Features
Features are the individual pieces of data that a model uses to make predictions. The quality and relevance of these features directly affect model performance.
Techniques
- Selection: Picking only the most important features.
- Transformation: Adjusting features for better model interpretation.
- Dimensionality Reduction: Simplifying data to avoid overfitting.
Model Deployment and Observability
Deployment Steps
- Serialization: Save models in formats like Pickle or TensorFlow SavedModel for easy reuse.
- Containerization: Package models using Docker for consistency across environments.
- APIs: Use frameworks like Flask or FastAPI to expose model outputs to applications.
Observability Platforms
Monitoring tools like Grafana and Prometheus allow real-time visualization of performance metrics, ensuring seamless operation and issue detection. At InfoBeans we have also built custom dashboards on top of Langchain to help evaluate model performance, cost and monitoring in real-time deployments.
Security-Focused AI/ML Practices
Data Management
We recommend these practices for data management security:
- Data Minimization: We only share the data that is necessary for the AI’s functionality to reduce exposure risks.
- Obfuscate PII: We apply hashing, tokenization, or other methods to de-identify personally identifiable information (PII) before interacting with models or third-party systems. We can also work with third party tools like Private AI or Data Sentinel.
- Add Noise: If necessary, we use statistical techniques such as adding noise to datasets to maintain privacy while preserving the utility..
- Access Controls: We enforce role-based access control and segment users into security groups to ensure that only authorized entities can access data.
The Role of Cloud Platforms in AI/ML
Comparing AWS, Azure, and Google Cloud
Each platform provides unique features:
- AWS SageMaker: Comprehensive tools for model deployment and monitoring.
- Azure ML: Strong integration with enterprise systems.
- Google AI Platform: Advanced tools for experimentation and scalability.
Best Practices
Adopt secure configurations, regularly update systems, and follow compliance guidelines specific to your industry.
Why InfoBeans is an AI/ML partner you can count on
InfoBeans brings expertise in:
- Data Engineering: From ingestion to deployment.
- MLOps: Tools and practices for efficient operations.
- Cloud Platforms: Proficiency in AWS, Azure, and Google Cloud.
With a proven track record, we deliver secure, scalable, and high-performing AI/ML solutions tailored to your needs.
FAQs
What is zero-trust architecture, and how does it work?
Zero-trust architecture assumes no entity is trustworthy by default. It enforces strict authentication and authorization for every interaction.
How can I secure PII in AI/ML projects?
Use obfuscation techniques like tokenization and hashing to protect sensitive data.
What tools are best for scalable pipelines?
Platforms like Apache Spark and Databricks handle large-scale data efficiently.
How does observability improve AI/ML workflows?
Observability tools like Grafana allow real-time tracking of metrics and anomalies, ensuring smooth operation.
Why choose InfoBeans for AI/ML projects?
We combine technical expertise, security best practices, and scalable solutions to deliver successful outcomes.

Related content
Mobile Development
We design and build custom enterprise mobile applications from the ground up.

Salesforce
Implementation review – technical and design. Sales, Service, Finance, Insurance cloud, CPQ, Mulesoft, Digital Twin, Security, innovative & solution-first approach.
Cloud
Ensure secure migration of your data to a more efficient environment – Public, Private or Hybrid Cloud



Stay up to date with InfoBeans
Insights from our team of experts who deliver digital software day in and day out.
![]() Thank you for signing up!
Thank you for signing up!
![]() Thanks a lot for your interest. You are already a subscriber. You will receive your first newsletter soon.
Thanks a lot for your interest. You are already a subscriber. You will receive your first newsletter soon.
